You can find me on Mastodon, where I am quite active, and on LinkedIn (I have stopped using most of the other global social-media systems). I have also been blogging, intermittently, since 2003. These days, I generally write about my work in the areas of scholarly-communication, open-access repositories, software development & research-data management.
My company is Antleaf.
I am also a member of the International BBQ Planning Committee.
Current Work (Selected Projects)
 Antleaf
Antleaf
My digital consultancy working in the higher-education and research domains, with particular expertise in scholarly communications, repositories and related infrastructure.
 COAR Technical Consultancy
COAR Technical Consultancy
I provide ongoing technical consultancy to the Confederation of Open Access Repositories (COAR), working closely with the Executive Director.
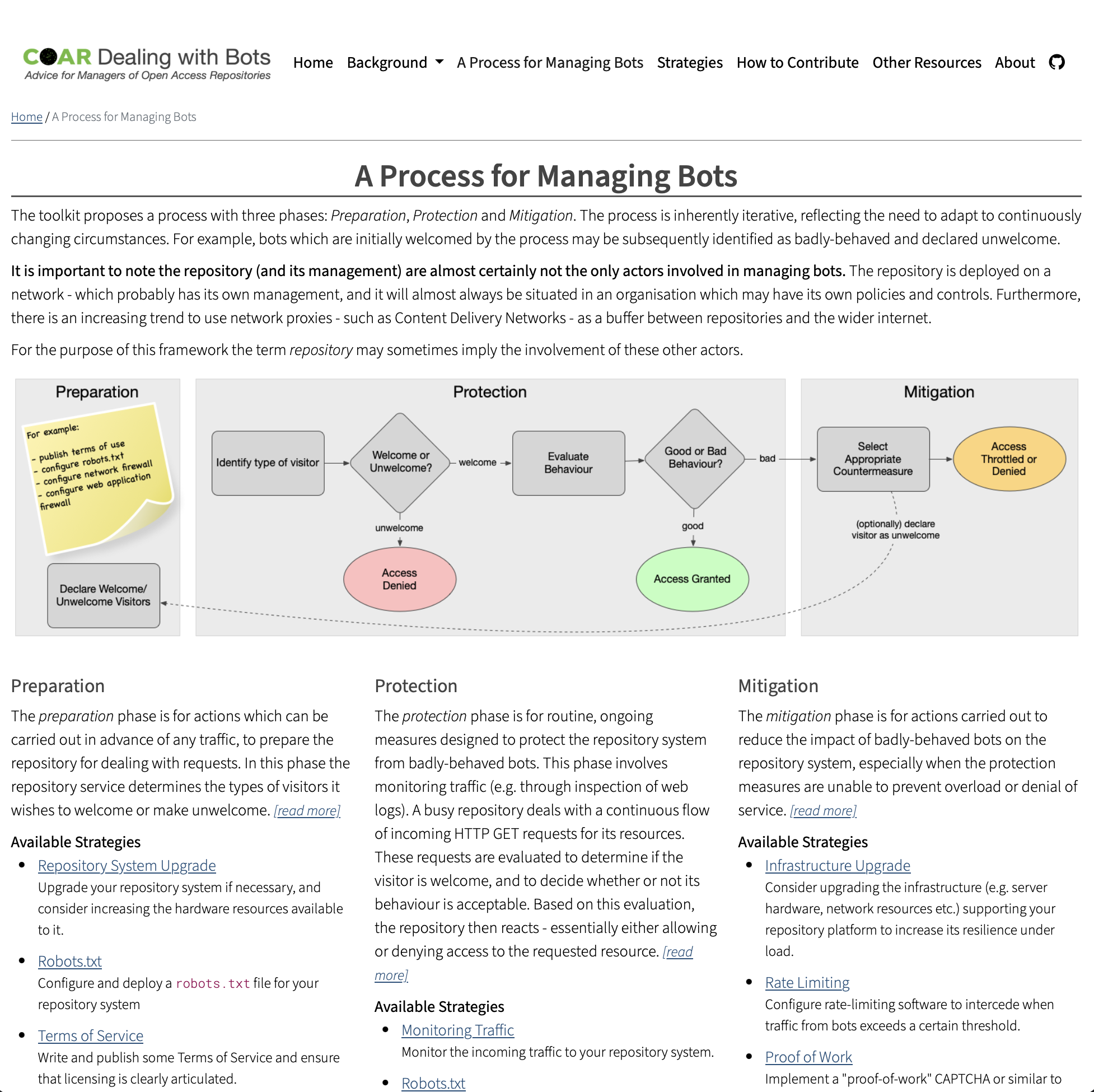 The Dealing With Bots Web Resource
The Dealing With Bots Web Resource
A web resource to help repository managers understand the challenges posed by bots, and to provide guidance on how to manage bot traffic effectively.
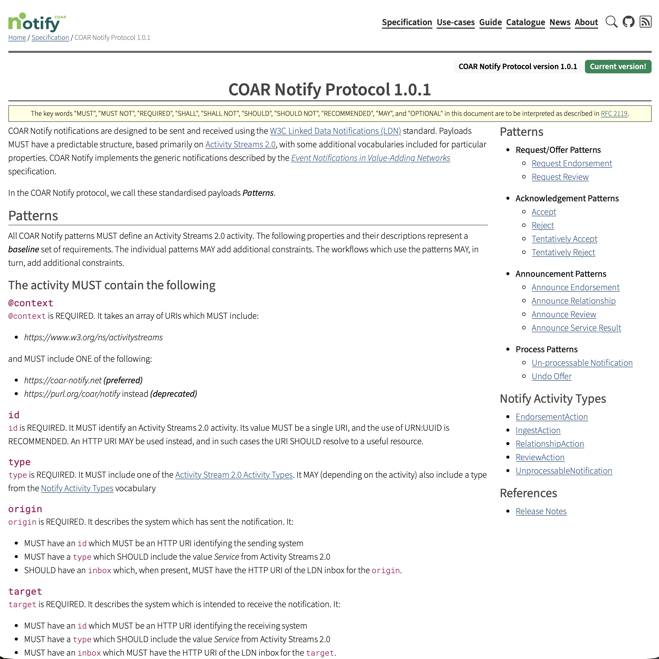 The COAR Notify Protocol
The COAR Notify Protocol
A set of profiles, constraints and conventions around the use of W3C Linked Data Notifications (LDN) to integrate repository systems with relevant services in a distributed, resilient and web-native architecture.
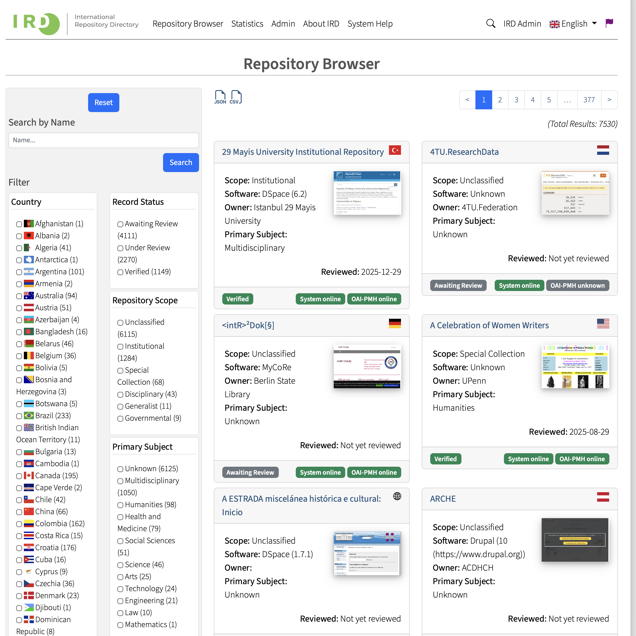 International Repositories Directory (IRD)
International Repositories Directory (IRD)
I built and help to maintain COAR's International Repositories Directory (IRD). The directory aims to be an authoritative source of information about Open Access repositories.
 Rioxx
Rioxx
Rioxx is a metadata profile, designed to aid open-access repositories to share metadata about the scholarly resources they contain.
Most Recent Blog Posts
- Cognitive Sovereignty
- Opening Up the Land Registry
- Experimenting with
human.json - A Library is a Civic Statement
- Dropbox Ignore Rules - At last!
- Figshare's OAI-PMH Interface is Broken
- Generation Augmented Retrieval
- Throwing Muses, Electric Ballroom, Camden
- Supreme Court backs wild camping on Dartmoor
- Using CloudFlare Turnstile to protect certain pages on a Rails app
Selected Presentations


9 Oct 2024
Ecole Nationale Superieure des Sciences de l'information et des Bibliotheques, Lyon


19 Jan 2012
Radcliffe Training & Conference Centre, The University of Warwick


1 Mar 2010
VeRSI (Victorian eResearch Strategic Initiative), Melbourne University